Web Development with CVS
Introduction
Versioning control is a concept that has been around for quite some time. It turns out that it works extremely well for web development as well. In many development environments several programmers and or designers might be working on the same project at once. This can make it difficult for the team to keep track of who made what changes, or which files are being worked on at what time. In order to help to ease this burden, and to add an extra layer of backups to the systems, many organizations choose to use CVS for versioning control.
This article aims to demonstrate how to deploy and use CVS for web development. The article assumes that developers are working on Windows based workstations but that the servers hosting the web applications are Unix or Linux based. Graphical tools exist for both Linux and Windows workstations, but I am going to assume that developers on Linux workstations are already familiar with this model of software development.
Isolating and Resolving Changes
CVS acts as a software repository. CVS is designed to be the 'system of record' during the software development cycle. Whenever a developer needs a copy of the software they simply check it out. When a check out request is made the CVS system extracts a complete copy of the most recent version of the code for the requestor.
This may seem awkward at first to many web developers. Often web developers are accustomed to working with the 'live' files on the server file system. This is a bad idea and can lead to lots of problems. Not only can mistakes bring down the web system, but even if you have a separate development environment what happens when you have two developers working at the same time?
In an ideal environment developers should be free to work on whatever software they want, whenever they want. Having a local testing environment allows the developer to make changes to software, test the results, and refine their work in isolation. This is important because it confines software changes during the development session to those created by the developer. This means that another developers changes won't affect the local developers work.
For instance, assume Joe and Sally are working on the same application. Joe begins work on the user authentication module. Sally is working on the database interface. Joe makes several changes and begins to test the results, but he finds that after the changes the authentication is completely broken. At this point Joe can't be sure if the authentication stopped working because of the changes he made, or if it was because of changes that Sally made. If Joe and Sally each work on their own copies of the software then they can track bugs much more easily. Of course, utilizing this model might create some immediate problems. What if Joe makes changes to a file and Mary makes different changes to the same file?
This is where CVS comes into play. CVS acts as a smart file storage. CVS keeps track of revisions to a file as well conflicts. When a conflict occurs CVS will attempt to resolve the conflict on it's own, often very successfully. In the rare occurrence where changes conflict directly, CVS will prevent the check in of a file until the conflicts are resolved. So if Sally checks in a version of a file, CVS will update the repository and when Joe tries to check in his version of the same file that conflicts directly with Sally's, CVS will alert Joe to the conflicts and require him to rectify the conflicts on his end before he can check the file back into CVS.
Some coordination will still be necessary of course. If Joe deletes an entire method from a class library and checks the file back in CVS will not be able to determine if that method was necessary for other files to function. CVS will, however, keep track of the versions of that file, so if the error is discovered you can roll back the changes and recover previous versions of a file.
The Role of CVS
So at this point we assume that we have different developers all working on local copies of the software. They all have their own web servers set up and are connecting to their own databases. They begin by checking out copies of the code from CVS, updating their local versions, and checking the changed files back into the central repository. At this point, however, there is no 'development' environment for outside parties or managers to review. While there are test environments for all the developers we need to get the web application deployed on a server. To do this often times organizations will employ two separate systems. One of these systems is the 'staging' environment, the other is the 'live' environment. The staging environment is used to view changes. When all the coders are done with a round of revisions and they've checked back in their changes you can tag the status of the CVS system, basically marking all the versions of the files as a 'release'. CVS will keep track of the version numbers on each file and create an index so if you ever want to retrieve the entire repository from the state it was in at this tagging you'll be able to, even if further changes have taken place.
Once the release it tagged it is checked out to the staging environment. This allows everyone to look at a central copy of the software and evaluate and test it. If fixes need to be made then the developers can check out copies, make the fixes, and check them back in. Once all the necessary fixes are made you can create a release tag. This version is checked out to the staging environment and if it's approved it can then be checked out onto the live environment. This ensures that only fully vetted and tested software ends up on the live server, but still allows the developers, testers, and quality assurance staff the ability to look at the code and make changes.
This also means that you have several backups of your code. Each developer has a backup of the project on their local machine, there is a backup in the CVS repository, there is a backup on the staging server, and there is a copy on the live server. If you do rigorous backups of the CVS server as well then you've got pretty good redundancy.
So our final CVS development environment looks something like this:
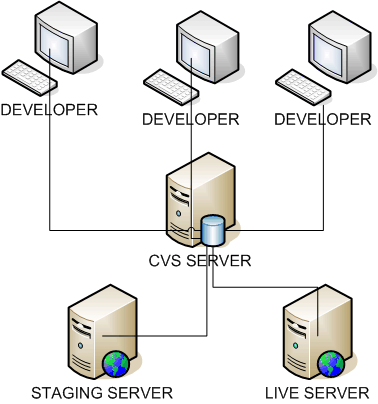
You can see how CVS serves as the central repository for the software, but how the software actually runs on several different machines.
Setting Up CVS
I won't go into the specifics of how to install and configure CVS since there are already a lot of great articles out there online. Instead I'll focus on the tools you'll need to make an effective environment.
You'll want to set up your central CVS server with SSH. CVS will allow you to check in and out of the repository over sftp or other secure channels. This ensures a level of protection for the information in transit as well as allowing further access controls.
You can potentially even utilize this same server as the staging and live host as well (each using their own web directory). In this way you can leverage the power of multiple environments even if you only have one host.
For the client machines it is easiest on Windows to use Tortoise. There are several CVS graphical tools for windows but I find this one to be the easiest to use. Tortoise is even bundled with it's own secure protocols, but it's often nice for developers to have a copy of PuTTY to do check outs to the staging or live server as well.
Once the developer machines are set up all they need to do is check out a copy of the repository into their own local web directory. From there, when they make changes, Tortoise will change the color of the file icon, indicating it has been modified and prompting the user to check the file back in. The user can then point and click from that point out to update their local check out or check in files. They can even tag the files they check back in with revision notes indicating the changes that they made. This allows users to inspect the version history on files and find a complete log of what changes were made at what time by which developer (no more exhaustive revision data in header comments).
Since CVS can be configured to work over secure protocols, you can even put the CVS server in it's own location. Then the staging and development environments can be physically separate from the CVS server and can check out and update local copies of the repository when changes are made. With careful tagging you can even keep control over releases and roll backwards to previous releases as quickly as a single command. This also makes updating applications as simple as issuing a CVS update function from within the context of the development or staging server. It also means that none of the developers have direct access to the files which helps to insure the integrity of the "live" application.
Recommended Reading and Related Sites
- CVS Site
- Essential CVS - the O'Reilly Manual
- Tortoise CVS
- WinCVS - another Windows GUI
- Windows based CVS